刘高军,王 岳,段建勇,何 丽,王 昊
(1.北方工业大学 信息学院,北京 100144;
2.CNONIX 国家标准应用与推广实验室,北京 100144;
3.富媒体数字出版内容组织与知识服务重点实验室,北京 100144)
口语理解(Spoken Language Understanding,SLU)是任务型对话系统的关键组成部分,通常包含意图检测和槽填充2 个相互关联的子任务。其中,意图检测需要完成对口语语句整体意图的分类,槽填充则标注句子中的关键语义成分。
近年来,以基于Transformer 的双向编码器表示(Bidirectional Encoder Representations from Transformer,BERT)[1]为代表的基于预训练的语言模型在各领域中都得到了广泛的应用,并在多项任务中表现出优异的性能。文献[2]验证了BERT 模型在SLU 任务中极其优异的性能表现。然而,以BERT 为代表的语言模型只能建立文本的上下文关联,而缺少丰富的外部知识来支持其完成更为复杂的推理。基于这一背景,研究人员开始尝试通过为语言模型融合知识进行迁移训练来提升其在特定任务中的性能表现。文献[3]通过使用注意力机制为BERT 融入外部知识来提升其在机器阅读理解任务中的性能表现。而在口语理解领域,则较少有研究人员进行该方面的研究。与文献[3]相同,研究人员使用2 个知识库为BERT 提供外部知识,记录单词间语义关系的WordNet[4]以及保存了实体概念的NELL(Never-Ending Language Learning)[5],它们分别为模型提供了语言学知识和真实世界知识,使用KB-LSTM[6]提供的100 维预训练嵌入来对知识进行表示,通过这些外部知识来提升模型对于模糊、以及可能存在错误语句的理解能力,并赋予模型更加优秀的复杂推理能力。
由于口语理解任务包含了意图检测和槽填充这2 个相关联的子任务,近年来出现了大量的联合模型,旨在通过此原理,利用各种联合训练机制提升模型在口语理解任务中的性能表现[7-9]。例如:文献[10]将编码器-解码器结构和注意力机制引入到口语理解任务中,使2 个子模块使用共同的编码器计算损失函数来实现联合训练;
文献[11]通过门控机制为槽填充引入意图信息来提升模型的性能表现;
文献[12]提出了循环运行的子网络结构,使2 个子模块互相利用对方产生的特征信息提升各自的性能表现;
文献[13]通过引入单词级别的意图检测和堆栈传播机制[14]来提升模型的性能表现。
本文提出一种针对口语理解任务的基于BERT 的联合模型。该模型引入单词级别的意图特征,使用注意力机制为BERT 融入外部知识,通过外部知识的联合训练机制提升其在口语理解任务中的性能表现。最终在ATIS[15]和Snips[16]2 个公开数据集上进行了实验。
下文通过4 个模块对本文模型进行介绍:
1)BERT 编码器和意图编码器:为每个口语语句输出其对应的单词级别的语义槽值特征和意图特征。
2)知识整合器:通过注意力机制将每个单词所对应的多个知识嵌入进行加权运算并得到相应的知识向量。
3)知识注意力层:使用前2 个模块的输出来计算单词级别的知识上下文向量。
4)知识解码器:以单词级别的意图特征、语义槽值特征和知识上下文向量作为输入,经过计算给出单词级别的意图输出和语义槽值输出。
在上述4 个模块中,知识整合器和知识解码器是模型中最重要的2 个模块,它们分别完成了融合知识和联合训练这2 个重要的步骤。
1.1 模型构成
1.1.1 BERT 编码器和意图编码器
如图1 所示,BERT 编码器和意图编码器会为每个口语语句输出其对应的单词级别的语义槽值特征和意图特征。

图1 BERT 编码器和意图编码器的结构Fig.1 Structure of BERT encoder and intent encoder
另外,由于BERT 输出的特殊向量[CLS]中蕴含了整个句子的意图特征信息,因此使用其作为单向LSTM 的初始隐藏层状态输入h0。
1.1.2 知识整合器
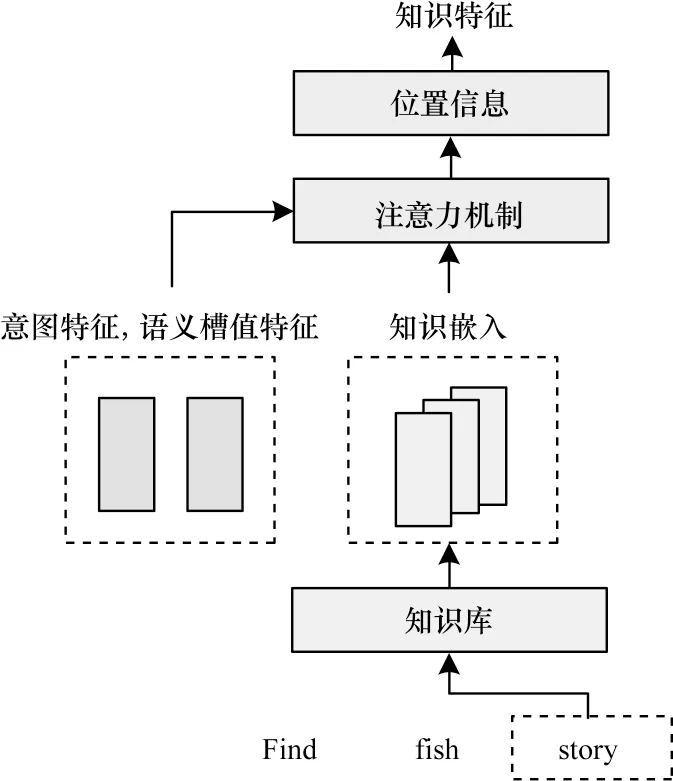
图2 知识整合器的结构Fig.2 Structure of knowledge integrator
其中:Wc是经过训练所得到的2d×100 维权重参数。在得到相关性系数αi,j后,通过式(3)进行加权计算得到单词xi的100 维知识特征ki:
为单词级别的知识特征K=(k1,k2,…,kT)添加位置信息,位置信息的计算方法与文献[19]相同。具体地,对于单词xi,使用式(4)和式(5)计算与之对应的100 维位置嵌入pi:
其中:i表示单词在句子中的位置;
j代表知识特征向量的下标位置。通过将单词xi所对应的100 维单词级别知识特征ki与100 维位置嵌入pi按位相加,得到包含位置信息的知识特征ki=ki+pi。
1.1.3 知识注意力层
知识注意力层使用前2 个模块的输出来计算单词级别的知识上下文向量。
其中:Wk是经过训练所得到的d×100 维权重参数。然后,通过式(7)进行加权计算得到单词xi的100 维知识上下文向量ei:
对知识上下文向量进行层标准化[20]处理,得到与输入语句X=(x1,x2,…,xT)所对应的知识上下文向量E=(e1,e2,…,eT)。
1.1.4 知识解码器
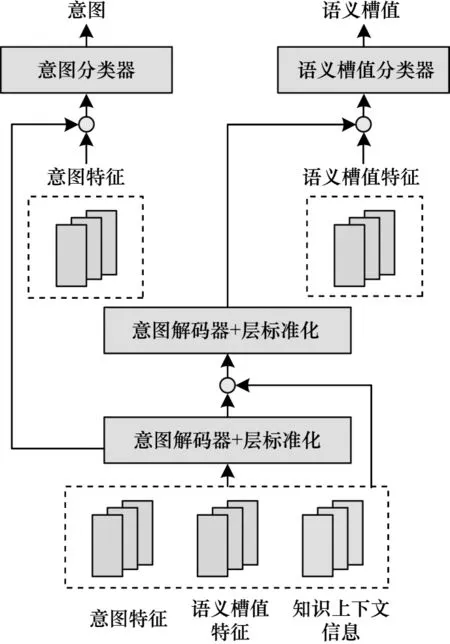
图3 知识解码器的结构Fig.3 Structure of knowledge decoder
1.2 意图的合成
对于输入语句X=(x1,x2,…,xT),还需要根据它的单词级别意图检测结果计算得出句子级别的意图预测结果oI。计算方法如式(14)所示:
其中:m是句子的长度;
nI是意图标签的数量;
αj表示一个第j位为1 且其他位为0 的nI维0-1 向量;
argmax表示返回α中最大值的索引操作。
1.3 联合训练
由于模型引入了单词级别的意图特征并进行了单词级别的意图检测和槽填充,为了最大限度地利用这些特征,使用式(15)~式(17)来计算模型的损失值L:
2.1 知识表示和检索
本文选择WordNet和NELL(Never-Ending Language Learner)2 个知识库构成模型最终使用的知识库。WordNet 是一个英语语义数据库,它根据词汇的细分词义概念对其进行分组,将有相同词义的词汇归为一个同义词集合。WordNet 为每一个词义提供了简短的定义,并记录不同的词义之间的语义关系,如felidae 和cat 的关系是hypernym_of。NELL 通过互联网挖掘的方法自动抽取并保存了大量的三元组实体概念知识,如(Google,is a,company)。之所以选择这2 个知识库是因为两者存储的知识构成了互补关系,WordNet 为模型提供语言学知识,NELL 为模型提供真实世界知识,从而帮助模型获取比文本更细粒度的特征信息。
2.2 数据集
通过在ATIS 和Snips 公开数据集上进行的一系列实验验证了模型出色的性能表现。2 个数据集均采用与文献[11]相同的数据划分。ATIS 数据集收录了用户预定、查询航班信息时的录音数据,在训练集、开发集和测试集中分别含有4 478、500 和893 条语句。训练集中还含有21 个意图标签和120 个语义槽值标签。Snips 数据集收录了个人语音助手Snips的用户数据,在训练集、开发集和测试集中分别包含13 084、700 和700 条语句。训练集中含有7 个意图标签和72 个语义槽值标签。
2.3 实验设置
使用基于英语的无大小写BERT-Base 模型进行微调训练,该模型含有12 层、768 个隐藏层状态和12 个注意力头数。在微调训练过程中,根据模型在开发集上的效果来选择所有超参数的取值。语句最大长度为50,每个单词的最大知识数为80。对于ATIS 和Snips 数据集,批大小分别被设置为16 和64,分类器的遗忘率分别为0.2 和0.1。此外,使用初始学习率为5e-5 的Adam[21]作为优化器。
2.4 实验结果
模型在2 个数据集上的性能表现如表1 所示。使用准确率和F1 得分来评估模型在意图检测和槽填充2 个子任务中的效果,用句子级别的语义准确率来评估模型的整体性能表现。的模型性能表现。从实验结果可以看出:与融合2 种知识模型相比,模型在2 组数据集上的性能表现均出现了下滑,且仅融合WordNet 知识和仅融合NELL 知识的模型在ATIS 数据集上的性能表现均优于无任何知识的模型,而在Snips 数据集上,仅融合NELL 知识的模型虽然在整体的性能表现上略低于不融合外部知识的模型,但在意图检测和槽填充这2 个子任务上均优于后者。

表1 本文模型在2 个数据集上的性能表现Table 1 Performance of the model in this paper on two datasets %
表1 的第1 部分是基准模型,由2 个基于BERT的联合模型BERT SLU[2]和BERT+Stack-Prop[13]组成。这2 个模型均在2019 年被提出,且相比基于循环神经网络(Recurrent Neural Network,RNN)[22]、卷积神经网络(Convolutional Neural Network,CNN)[23]、条件随机场(Conditional Random Fields,CRF)[24]及支持向量机(Support Vector Machine,SVN)[25]的传统口语理解模型具有更加优秀的性能表现。其中,BERT SLU 仅使用BERT 完成口语理解任务,BERT+Stack-Prop 则引入堆栈传播机制来提升BERT 在口语理解中的性能表现,本文分别使用BERT 和BERT+堆栈作为这2 个模型的简称。
第2 部分则展示了BERT 在融合外部知识之后的性能表现,本文简称为BERT+知识。可以看出,融合外部知识后,BERT 模型在2 个数据集上均有着超过基准模型的性能表现。在ATIS 数据集上,与仅使用BERT 的BERT SLU 相比,在意图准确率中获得了0.4 个百分点的提升,且在句子级别的语义准确率这一指标上获得了0.9 个百分点的提升。在Snips 数据集上,模型在槽填充F1 得分中获得了0.2 个百分点的提升,且在句子级别的语义准确率这一指标上获得了0.5 个百分点的提升。
通过以上分析可以看出:
1)引入外部知识可以提升BERT 模型在口语理解任务中的性能表现。
2)引入单词级别的意图特征提高了知识融合的效果。
3)联合训练机制能够利用外部知识计算,得到可以被特定子任务使用的特征信息。
通过设置多组消融实验,从不同的角度验证了上述方法的正确性。
2.5 引入知识的效果
使用以下3 个模型进行消融实验来验证引入外部知识对模型性能的提升作用:
1)不引入任何知识,仅让知识解码器以单词级别的意图特征和语义槽值特征作为输入进行联合训练。
2)仅为模型引入WordNet 所提供的语言学知识。
3)仅为模型引入NELL 所提供的真实世界知识。
可以从表2 的第1 部分看到3 个参与消融实验
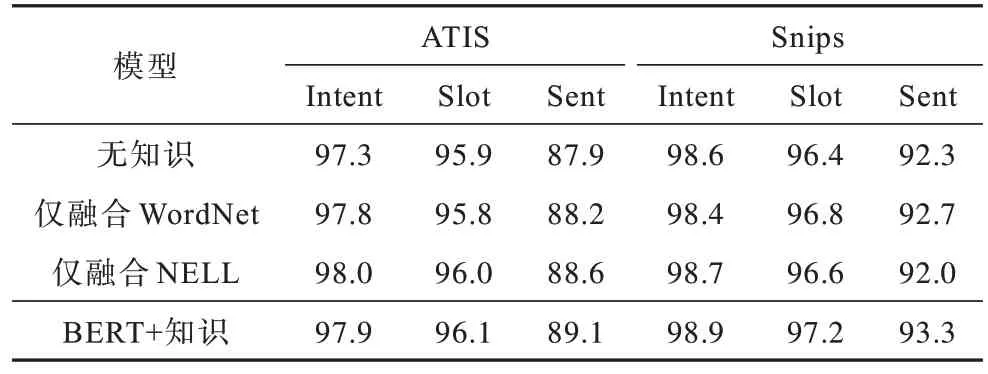
表2 融合不同外部知识对模型性能的影响Table 2 Effect of integrate different external knowledge on model performance %
从表2 可以看出:融入知识模型可以有效提升模型的性能表现,并且在一定程度上体现了WordNet 和NELL 这2 个知识库可以有效互补。
2.6 引入单词级别的意图特征效果
引入一个仅使用句子级别意图特征的模型作为对照,验证引入单词级别的意图特征对模型效果的影响。该模型不使用LSTM 对输入语句的每个单词映射出与之对应的单词级别意图特征,而使用BERT编码器输出的特殊向量作为每个单词的意图特征。
从表3 所示的实验结果可以看出:引入单词级别的意图特征可以进一步提高模型的性能表现,这可能是因为句子级别的意图特征在融合知识和联合训练的过程中无法有效涵盖每个单词的语义特性。此外,使用句子级别的意图特征也不利于通过注意力机制来计算2 个单词间的相关性。
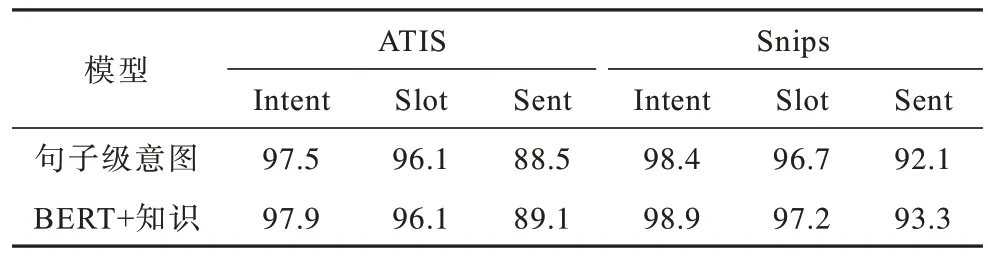
表3 单词级别意图特征对模型性能的影响Table 3 Effect of word level intent feature on model performance %
2.7 引入位置信息的效果
在知识融合器中,通过注意力机制来对知识嵌入做加权求和得到单词的知识向量。如果不为知识嵌入加入位置信息,那么这些向量就难以在接下来的注意力计算中反映彼此的位置关系。为了验证上述观点,设置一个不会在知识融合过程中为知识向量添加位置信息的模型作为对照组。
从表4 可以看出:引入位置信息可以进一步提升模型的性能表现,也同时验证了上述猜想的合理性。
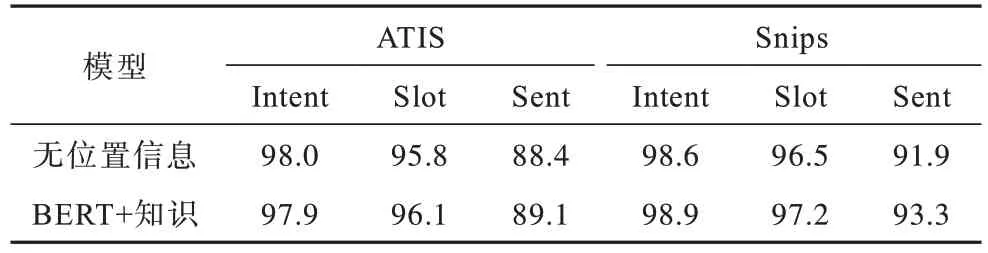
表4 位置信息对模型性能的影响Table 4 Effect of location information on model performance %
2.8 引入联合训练机制的效果
引入联合训练机制的消融实验验证了联合训练对模型性能的提升。实验中使用2 个模型作为对照:
1)将意图解码器和语义槽值解码器从模型中删除,用知识上下文向量来替代这2个解码器所输出的特征信息。
2)使语义槽值解码器不再以意图解码器输出的特征作为输入,让2 个解码器独立运行。
如表5 所示,在2 个数据集上使用2 个独立解码器的模型在性能上优于不含解码器的模型,且低于使用2 个相关联解码器进行联合训练的情况。这表明在2 个子任务所对应的解码器之间引入联合训练机制可以进一步提升模型的性能表现。

表5 联合训练机制对模型性能的影响Table 5 Effect of joint training mechanism on model performance %
2.9 案例分析
从ATIS 数据集中选择2 个案例来体现模型在引入外部知识后相比BERT SLU 的性能提升。
从表6 可以看出:虽然BERT 使用大量的文本数据集来进行训练,它仍然无法正确地标记“michigan”的语义槽值。而本文提出的模型却因为融合了NELL 提供的真实世界知识而正确地判断了密歇根是美国的一个州而非一座城市。

表6 NELL 知识对模型性能的影响Table 6 Effect of NELL knowledge on model performance
表7 所示的案例则体现了本文模型在应对逻辑复杂不清晰的口语语句时具有更强的性能表现。在表7的复杂语句中,本文模型识别出了2 个“milwaukee”之间隐含的逗号分隔符,成功地构建出了这条语句中的内部逻辑关系。这是因为WordNet所提供的语言学知识使模型性能得到了提升。

表7 WordNet 知识对模型性能的影响Table 7 Effect of WordNet knowledge on model performance
本文提出一种基于BERT 的联合模型,旨在验证预训练语言模型融入知识进行迁移学习这一方法在口语理解领域的可行性。通过引入单词级别的意图特征并使用注意力机制为模型融入外部知识,并使用联合训练机制来提升模型在口语理解任务中的性能表现。在ATIS 和Snips 这2 个公开数据集上进行的实验结果表明,该模型相比BERT 模型具有更好的性能表现。后续将继续寻找更为高效的可融合知识的联合学习机制,并探索跨语言知识融合方法,通过融合外部知识提升口语理解模型的性能。
猜你喜欢解码器级别意图原始意图、对抗主义和非解释主义法律方法(2022年2期)2022-10-20陆游诗写意图(国画)福建基础教育研究(2022年4期)2022-05-16科学解码器(一)小学生必读(低年级版)(2021年10期)2022-01-18痘痘分级别,轻重不一样基层中医药(2021年8期)2021-11-02制定法解释与立法意图的反事实检验法律方法(2021年3期)2021-03-16科学解码器(二)小学生必读(低年级版)(2021年11期)2021-03-09科学解码器(三)小学生必读(低年级版)(2021年12期)2021-03-04线圣AudioQuest 发布第三代Dragonfly Cobalt蓝蜻蜓解码器家庭影院技术(2019年8期)2019-12-04迈向UHD HDR的“水晶” 十万元级别的SIM2 CRYSTAL4 UHD家庭影院技术(2018年5期)2018-06-29新年导购手册之两万元以下级别好物推荐家庭影院技术(2018年3期)2018-05-09