张梓浩 刘鹏浩 谢汉辉 邵国林 吴振凯 张嘉利
(广州工商学院,广东 广州 510850)
图像识别技术逐渐普及,不仅应用于日常生活,在消防安全应用方面更有它的一席之地。电动车因具有便捷、轻巧、无污染等优点,成为广大民众出行的重要选择,但是电动车电瓶存在安全隐患。近年来,电动车在室内、电梯内发生自燃、自爆的事件屡见报端,这些现象严重危害到了居民的生命、财产安全。如何正确进行电动车停放、充电关系到其居民的生命和财产安全问题。
2021年,中国消防公众号发布的《琼色:今年以来发生电动车火灾1万多起》中指出:“目前全国电动车保有量已经超过3亿,今年以来全国已经发生电动车火灾1万多起并造成人员伤亡,这集中反映了电动车消防安全治理的紧迫性、严峻性、复杂性。”
现如今,仍然有不少城乡居民习惯将电动车进楼入户停放、充电,更有将其停放在门厅、楼梯间、疏散走道等公共区域,一旦起火燃烧,其产生的高温有毒烟气将会迅速充满整个空间和消防通道,导致疏散、逃生困难,造成人员伤亡。因此,针对电动车充电不规范发生火灾和电动车是否在道路规范行驶的安全问题,本文基于深度学习的电动车智能检测系统,实现电动车自动识别并告警,从而起到督促监督的作用。
2.1 YOLOv3算法
YOLOv3[3]是一个端到端的回归网络模型,其基础网络是Joseph Redmon设计的Darknet-53网络架构(该网络中包含53个卷积层),由连续的3×3和1×1卷积层组合而成。由于主干网络设计为全卷积层,所以特征图的尺寸的修改是通过卷积层来实现的。YOLOv3算法核心主要分为三点:特征提取,网络预测和网络模型。特征提取是将图片的整个区域一同进行训练,在保持训练速度的同时,还可以很好地分辨出背景以及要区分的目标,但缺点是在面对比较大的目标时,会将其背景的一部分算入目标当中从而导致误差增加。网络预测是将一张图片分割成S×S个网格,若物体出现在某个网格上,该网格会对它进行识别检测。网络模型则是最为重要的,是本文中提到的YOLOv3的主干网络Darknet-53。
2.1.1 YOLOv3的Darknet-53网络
Darknet-53[4]是YOLOv3的主干网络,是在YOLOv2基础上的改进。相对于YOLOv2,YOLOv3提高了检测精度和检测速度,能够获取更佳的检测结果。
Darknet-53网络共有53层,每一层的均由卷积层、BN层和Leaky ReLU层组成,即每一层为一个DBL模块。DBL将卷积层的步长设置为2进行采样操作,同时利用BN层和Leaky ReLU层防止数据过拟合。采取此操作使得Darknet-53取消了Darknet-19的最大池化操作。同时,拼接采样后网络中间层和后面层的特征,呈现出特征融合的结果。图1为Darknet-53网络。

图1 Darknet-53网络
2.2 MoblieNet网络
MoblieNet[1]模型是一种基于深度可分离卷积的分解卷积形式,将标准卷积分解为深度卷积和称为逐点卷积的1×1卷积,如图2所示。

图2 MoblieNet网络
深度可分离卷积将标准卷积分解成Dk×Dk的深度卷积和一个1×1的点卷积[2]。MolibeNet模型里的深度卷积将单个过滤器应用于每个输入通道,然后逐点卷积应用1×1卷积来组合深度卷积的输出。而标准卷积均在一个步骤中实现过滤输入和组合输入输出。深度可分离卷积将其划分在两层来进行,一个是用于过滤的单独层,另一个是用于组合的单独层。
假设步幅为1和填充的标准卷积的输出特征图计算如下:
深度卷积计算成本:Dk·Dk·M·DF·DF;
深度可分离卷积成本:Dk·Dk·M·DF·DF+M·N·DF·DF
将卷积划分为过滤和组合两层的计算成本:
由上述的标准卷积、将卷积划分为两步的公式可以看出,分解后显著减少了计算量和模型大小。
2.2.1 MobileNet系列中的MobileNetv1
MobileNetv1[4]为MobileNetv系列的第一代,它同样是基于深度可分离卷积的分解卷积形式,将标准卷积分解为深度卷积和称为逐点卷积的1×1卷积,相对于Darknet-53有效减少了计算量和模型大小。MobileNetv1的网络结构仅有28层网络,第1层采用标准卷积;
第2~25层采用深度可分离卷积操作;
第26~28层采用平均池化方式的池化层、全连接层以及Softmax层。MobileNte结构如表1所示。

表1 MobileNet结构
2.3 YOLOv3的主干网络替换
本文采用MobileNetv1替换YOLOv3的Darknet-53,通过替换YOLOv3的卷积网络实现消减主干网络中卷积运算的目的,从而实现运算处理速度的提升。图3为网络模型卷积替换,红色框内为替换部分。
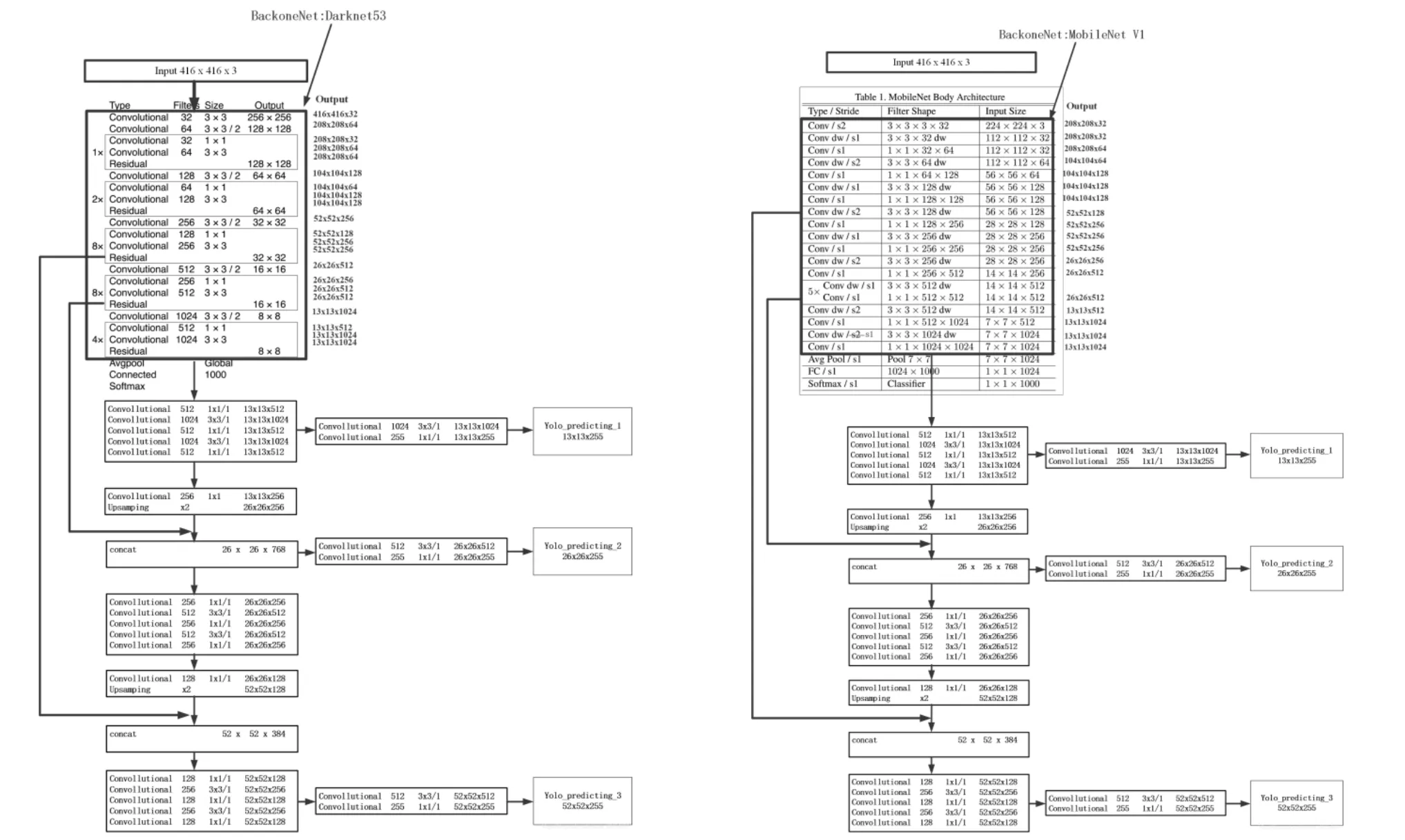
图3 网络模型卷积替换
2.3.1 YOLOv3的损失函数
损失函数[5]对于模型来说是判断其性能的重要参数之一,它用于预判出真实值与预测值的差值。YOLOv3的损失函数主要由三个部分相加组成,分别为:LOSScoor、LOSSconf和LOSScls。
LOSScoor是目标定位损失函数,利用中心坐标预测误差和边界框预测误差单独进行预方差来运算进而对目标框进行回归运算;
LOSSconf是置信度损失函数,该函数分有两种情况:有目标和无目标两种情况,在不含有目标损失当中引入权重系数;
LOSScls是分类损失函数,与交叉熵损失并同使用,更好地降低计算的复杂度。LOSS损失函数如下所示:
其中S2表示将一张图片分割成S×S个网格;
B表示共有B个预测框anchor box,anchor box为在预测对象范围进行约束,然后加入尺寸先验经验;
用于判断第i个网格中的第j个预测框里面是否出现所研究的目标,若有则将其值定义为1,否则其值定义为0;
相反用于判断第i个网络中的第j个预测框里面是否没有出现所研究的目标,若没有则将其值定义为1,否则其值定义为0负责网格的边界框是否担任预测某个实验对象,如果其担任则将其值改为1,否则其值改为0;
表示为拟合值。
2.4 数据采集以及预处理
2.4.1 实验环境
本文实验所采用的配置设备为GPU:Tesla V100.Video Mem:32GB.CPU:4 Cores.RAM:32GB.Disk:100GB。Pycharm软件平台在Python3.7版本下,使用Pytorch深度学习框架进行训练。
2.4.2 数据集
为了获取大量的数据,以及节省标注图片的时间,本文数据集采用pascal-voc和coco2017中的电动车数据作为本次的数据集。coco2017数据集共有80小类,其中交通工具分为8类:自行车、车、摩托车、飞机、公共汽车、火车、卡车、船。pascal-voc数据集共有20小类,其中交通工具分为7类:自行车、车、摩托车、飞机、公共汽车、火车、船,我们获取pascalvoc和coco2017当中摩托车类的电动车作为本文的数据集。其中pascal-voc有467张标注图片,coco2017有3502张未标注和8725标注框数量的图片,共有13694张图片,其中按照2:8的比例设置测试集和训练集。图4为数据集图片。

图4 上图为pascal-voc,下图为coco2017
2.4.3 实验步骤
(1)数据预处理及模型训练
数据集提取数据是指提取出CoCo数据集中的电动车类,并将其图片和坐标分别放在对应的文件夹中,将提取出来的数据转为voc格式,用于目标检测。定义训练次数为200次,将所有提取出来的图片一同训练200次。本文实验使用的模型为YOLOv3-MobileNetV1模型,将数据放入初始化好的模型进行训练。随后将模型导出,以便后续在pycharm做进一步实验。图5为搭建测试环境。

图5 搭建测试环境
(2)研究检测电动车并警报
运用安装好的OpenCV.cv2模块获取摄像头所拍摄的视频,按照一帧一帧的要求划分,运用cv2.imshow、cv2.imwrite等将提取出处理后的图片数据进行显示、保存操作,随后将其数据导入到训练好的模型中进行测试,然后将识别到电动车的图片导入到指定的文件夹中并将其以视频方式展示出来。图6为研究检测电动车并报警流程图。

图6 研究测试电动车报警
(3)制作桌面应用程序
PyQt5是基于图形程序框架Qt5的Python语言实现,由一组Python模块构成,Qt库是GUI库之一。在pycharm软件安装PyQt5模块,运用PyQt5模块编写出桌面应用程序实现结果可视化,然后将训练好的模型、搭建好的训练和测试环境、识别电动车代码等一系列环节一同打包为一款适用于大多数监控的桌面应用程序。图7为制作桌面应用程序流程图。
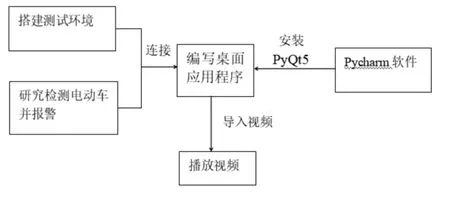
图7 桌面应用程序制作流程图
3.1 实验结果
本文针对识别电动车的检测任务,基于YOLOv3-MobileNetV1模型进行训练和检测,实现了对图片、视频和外接摄像头的电动车识别。图8为本文的电动车智能安全检测系统,实现图片、视频、摄像头的识别电动车系统。可以自行添加图片、视频或者连接外设摄像头识别。编写出简单实用的可视化桌面应用,内含四个按键以及两个展示区域,从左至右依次是打开图片,检测图片,视频检测和摄像头检测。展示区域从左至右依次是原视频和检测电动车的图片。

图8 电动车智能安全检测系统
3.2 网络模型卷积替换后性能对比
YOLOv3-MobileNetV1网络和YOLOv3网络检测模型的性能如图9。

图9 网络模型性能对比
由图9对比可知,YOLOv3网络的模型评估性能指标mAP(mean Average Precision)比YOLOv3-MobileNetV1网络的要高出约10%,但YOLOv3网络的FPS值比YOLOv3-MobileNetV1网络的要低,YOLOv3-MobileNetV1网络FPS值能达到26帧/s,而YOLOv3网络的FPS值只有16帧/s,能看出轻量级的目标检测网络可以通过减少通道数来提升自身的运算处理速度。
电动车消防安全问题一直是一个长期值得关注的难题。为了有效检测和警告电动车充电和停放的规范性,我们针对用户在给电动车充电和停放区域进行基于深度学习方法对电动车进行检测研究,以及时警告和督促电动车停放和充电规范性。本文使用YOLOv3-MobileNetv1模型进行训练和检测,实现了对图片、视频和外接摄像头的电动车识别,通过减少通道数提升了运算处理速度。但本文提出的电动车检测方法精确度仍有所不足,考虑从以下几方面进行改进:
(1)本文在模型训练中采用pascal-voc和coco2017中的电动车数据,仅有1057张电动车图片进行训练验证。考虑到电动车大小问题、距离的精确度,数据缺乏多样性,在未来需要增加更多电动车图片数据作为数据集从而提高精确性。
(2)由于MobileNetv3相对于MobileNetv1增加了具有线性瓶颈的倒残差结构和SE模块,考虑采用MobileNetv3替代MobileNetv1进一步探讨模型优化。
猜你喜欢电动车卷积深度电动车有可能没有高档和豪华车消费电子(2022年7期)2022-10-31基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02深度理解一元一次方程中学生数理化·七年级数学人教版(2020年11期)2020-12-14电动车新贵21世纪商业评论(2020年12期)2020-01-14卷积神经网络的分析与设计电子制作(2019年13期)2020-01-14从滤波器理解卷积电子制作(2019年11期)2019-07-04深度观察艺术品鉴证.中国艺术金融(2018年8期)2019-01-14深度观察艺术品鉴证.中国艺术金融(2018年10期)2019-01-08深度观察艺术品鉴证.中国艺术金融(2018年12期)2018-08-26基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20