李金鹏,徐兴荣,张冬梅,王雷,郑凯,刘聪
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
教育过程挖掘[1](education process mining, EPM)是教育数据挖掘(education data mining, EDM)的一个新兴课题,旨在发现教育数据集中隐含的过程性信息。随着各种教学支持环境的普及,使得捕捉不同粒度的在线事件成为可能,例如从鼠标、键盘的敲击动作到高级学习活动的获取,同时这些系统具有跟踪和记录各种不同实时数据的能力,如连续的敲击数据流、文本编辑的历史数据、动作追踪、学习资源使用记录等,过程挖掘[2]能够凭借这些记录发现并检测整个教育过程。教育过程的剩余时间预测可以作为EPM在时间维度上的应用。当前EMP已有的工作仅讨论模型能否准确还原教育过程,并在挖掘的基础上验证模型的契合程度,仅强调在线学习过程的挖掘与学生案例分析,鲜有研究在挖掘教育过程模型的基础上拓展其在时间维度上的应用。
为弥补这一空缺,本文引入长短时记忆神经网络(long short-term memory, LSTM)、门控制单元网络(gated recurrent unit, GRU)、双向(bi-direction)、注意力机制(attention mechanism)预测学生学习过程的剩余时间,采用MAE(mean absolute error)做为预测模型的评判标准,并设计一个应用架构论证学生学习过程的剩余时间预测在教学规划中的作用。本文应用架构以学生实时轨迹为输入,并预测实时轨迹的剩余时间,当监听到实时轨迹与优秀学生的过程模型发生偏移时,搜索前缀与实时轨迹一致且剩余时长与预测剩余时间误差最小的优秀学生轨迹并推荐;
当再次监听到实时轨迹发生偏移时再次推荐。该机制保证在优秀学生日志中能够搜索到与实时轨迹前缀匹配的优秀学生轨迹。
过程挖掘技术面向教育领域的研究尚处在初级阶段,过程挖掘之父Van Der Aalst院士在文献[2]首次提出将过程挖掘技术引入教育领域,同时期,在文献[3]描述了处理学习轨迹的方法,并用轨迹对齐策略研究学生的学习模式,在文献[4]扩展散点图的维度,尝试借助过程立方体建立可比较过程模型,分析荷兰学生和他国学生在学习过程上的区别。为了延伸教育过程挖掘的应用范围,文献[5]根据观看时长、评论字数等参数将表现相近的学生分为同一组,挖掘不同类别学生的学习过程;
文献[6]用模糊挖掘(fuzzy miner)算法发现学生的认知过程,同时借助建模工具构建理论上的认知模型用以重演真实的学生在线行为事件日志,提出了一种验证心理学理论模型的手段,使得过程挖掘技术的应用范围扩展到认知心理学研究。为了与传统机器学习模型结合,文献[7]将决策树与过程挖掘算法相结合,发现学生在Moodle平台上需要遵守的隐含行为规则;
文献[8]用支持向量机、过程相似度相结合的方式预测学生在OJ系统的表现。
运营和支持是过程挖掘的目的所在,在对现实场景的运营支持中,要考虑事前数据对案例下一步运行的影响,过程挖掘非仅局限于分析事后数据,同时可以为运行中的案例提供支持。第一类运作支持是检测运行时的偏差,即当偏差发生时及时反馈,文献[9]介绍如何用现有过程挖掘技术检测业务执行过程中发生的偏移(deviation),文献[10]引入多维度的declarative模型检测案例执行的一致性;
第二类运作支持是预测,即将轨迹的部分特征或相关属性映射到预测变量并做出响应,文献[11]用现有过程挖掘技术分析并预测制造过程的开销,文献[12]结合队列挖掘(queue mining)预测服务过程的延迟;
第三类运作支持是推荐,需要从事后数据中学习到一个模型,同时运作系统需要收敛一个决策空间,从而能够选择其中一个置信度最高的决策作为未来执行状态。
整合本文所提供的第二类运作支持教育过程控掘架构如图1所示。
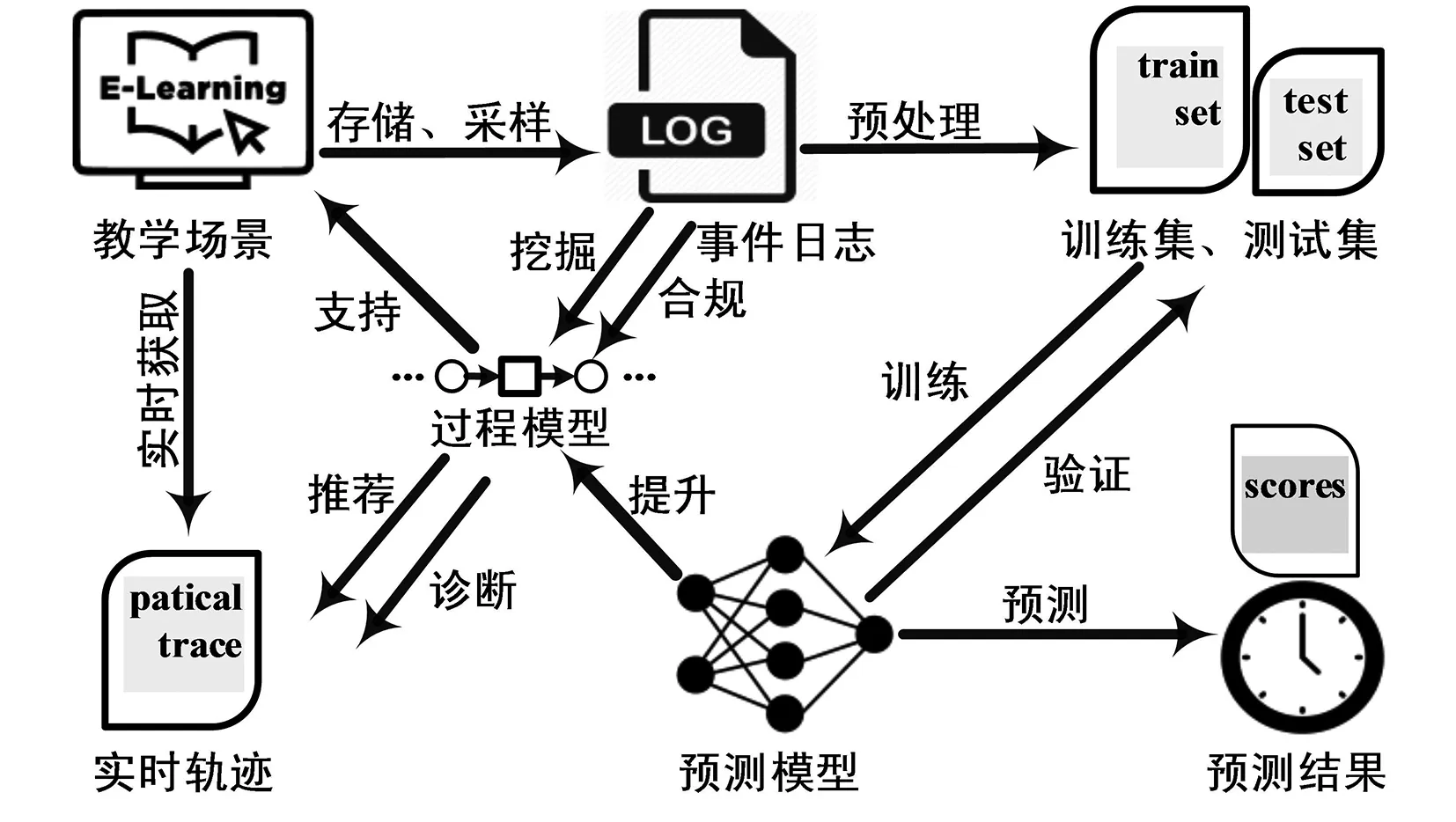
图1 教育过程挖掘架构
定义1事件(event):事件是组成日志数据的最小元素,可以是学习活动发生的一次实例,e=(act,id,studentId,resource,start,end,other),令A为活动名的集合,则act∈A,代表事件执行活动;id表示活动实例的唯一标识;studentId表示活动的执行者,即学生的标识; resource表示实例运行所需的资源;start、end分别表示该事件运行的开始和结束,当然,同一事件可以用更详细的属性类别描述;
other代指额外属性。设ε为事件集合,N为事件包含属性集合,若存在n∈N,对于其中任意一个事件e∈ε,#n(e)表示其属性n的值,令UC为案例集,UA为任务集合,UL为生命周期集合,UT为时间集合,假设对于任意一个事件e∈ε都包含属性:#case(e)∈UC为事件e所属的案例,即每个事件只能属于同一个案例;
#act(e)∈UA为事件e活动名;
#trans(e)∈UL为事件e的生命周期相关信息;
#time(e)∈UT表示事件e发生的时间戳。在本文所示课程案例中,鼠标的一次敲击,每个章节的一次观看,或者一次评论均可记录为一个事件,其中#section(e)表示学生发生事件e的章节名称。
定义2分类器(classifier):分类器的作用是根据事件的具体特征标识事件,定义为C:ε→UA×UL,即对于任意e∈ε,存在活动名#act(e)∈UA,#act(e)∈UL,若存在分类器C(e)= (#act(e), #trans(e)),设其生命周期取值范围是#trans(e)∈{start, suspend, reassign, complete},则该分类器将C(ei)=(act, start)标为acts,C(ej)= (act, complete)标为actc。在学生在线事件日志中,C(e)= (#section(e), #time.start(e), #time.end(e) )表示事件在轨迹中由章节名称、章节开始时间、章节结束时间组成。
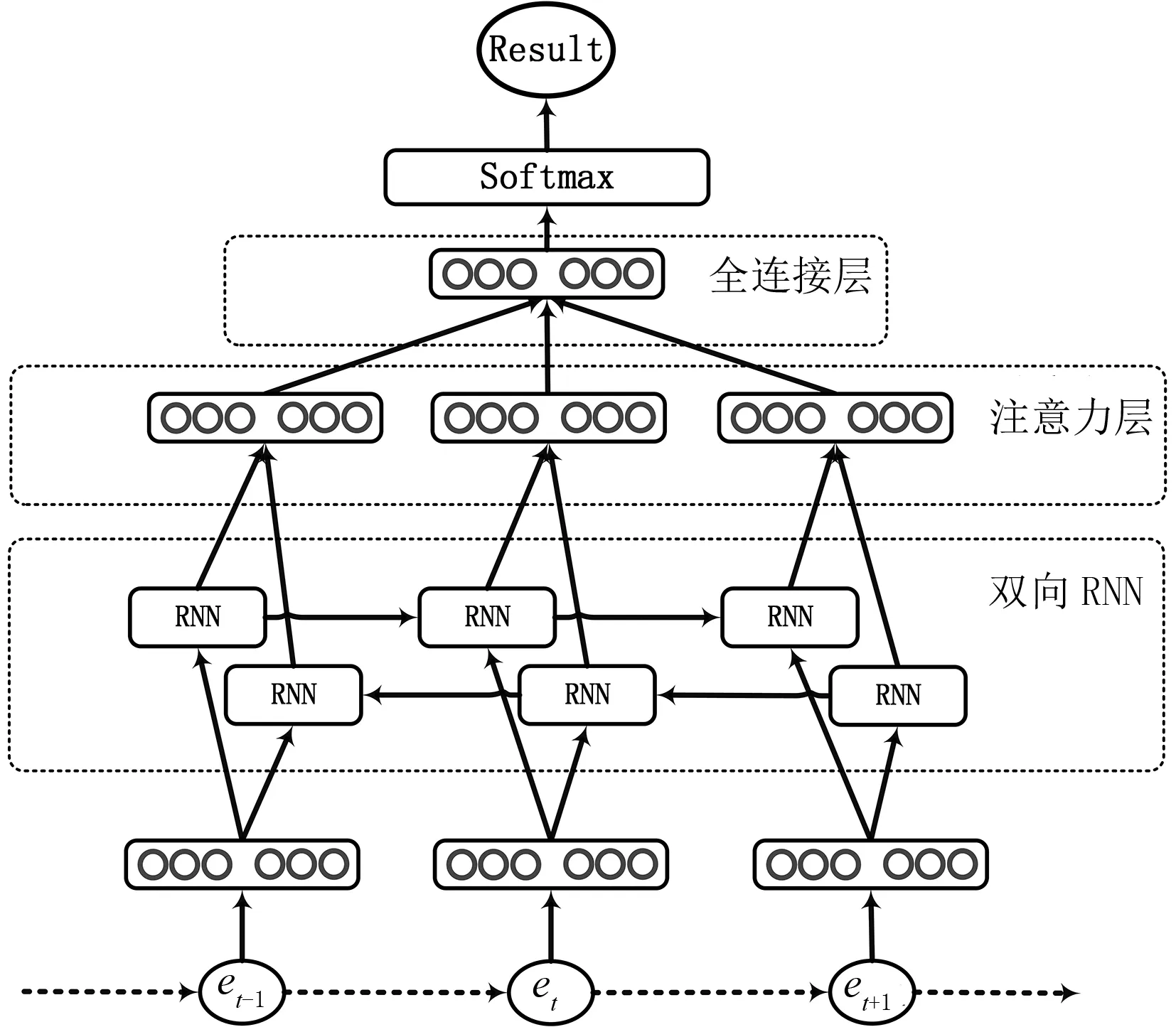
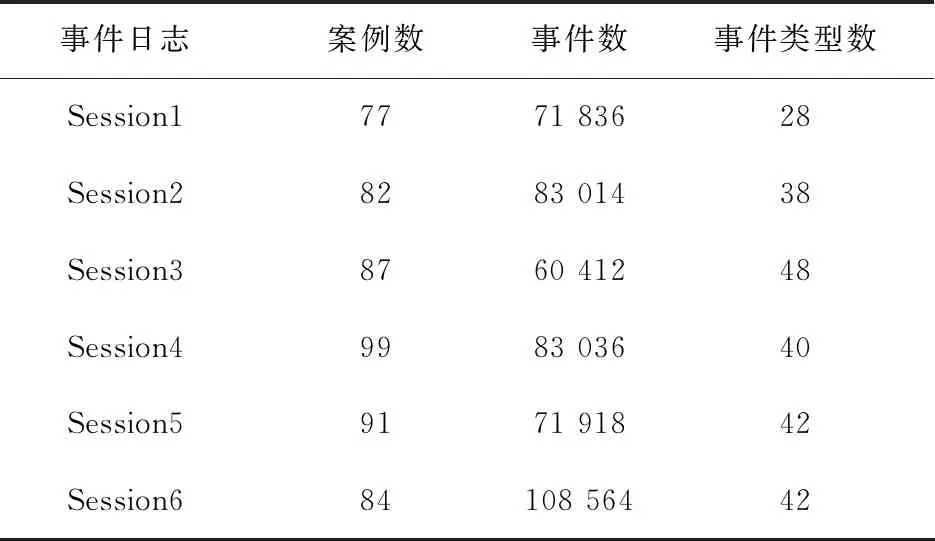
定义3轨迹(trace):轨迹是事件的有限序列,令ε*是定义在集合ε上任意长度有限事件序列组成的集合,案例(case)是有限的事件发生序列σ∈ε*,σ= 定义4轨迹前缀(prefix)形式化为σ(k)= 定义5Petri网(Petri net):Petri网[2]用于表示事物的演化过程,同时可以表示事物之间交互的控制流关系,在教学场景中,可以表示学习活动发生的顺序关系,Petri网由三元组N=(P, T, F)组成,T表示有限变迁(Transition)集合,P表示有限库所(Place)集合,其中F⊆((P×T)∪(T×P)),P∩T=∅为Petri网中表示控制流的弧集合,如图2所示,该Petri网表示为:F={ (start,a), (p1,b), (p2,c), (a, p1), (a, p2),(b, p3), (p3,d), (p4,d), (c, p4), (d, end) }; 图2 Petri网 训练集的获取思路是将教育事件日志L中的任意轨迹σi(1≤i≤|L|)截取为轨迹前缀σi(k),并标记σi(k)的剩余完成时间构建(σi(k), remain(σi,k))∈Dk,其中Dk是长度为k的轨迹前缀与其剩余时间组成的(σ(k), remain(σ,k))的集合,再整合∪Dk(1≤k< |σ|max)为输入模型的数据集合。详细描述如算法1所示。 算法1 GetTrainSet输入:前缀σ(k)的最小长度lmin(lmin >0),最大长度lmax(lmax< |σ|),事件日志L ;输出:∪Dk ;1.k = lmin ; D= ϕ2. FOR k ≤ lmax DO:3. Dk = ϕ4. FOR σ IN L DO:5. IF k ≤ |σ | THEN:6. Dk =Dk∪( σ (k), remain_time(σ, k) )7. END IF END FOR8. D =D∪Dk k++9. END FOR10.RETURN D; 最后,将∪Dk按照78∶22的比例分割为训练集与测试集,其中训练集用于拟合模型,测试集用以检验模型预测教育过程剩余时间的误差。 循环神经网络[13](recurrent neural network, RNN)是一类处理序列数据的神经网络,具有多种具体的实现方式,其中最具代表性的是LSTM和GRU。RNN支持可变长的输入序列,其基本特征是假设在较早的时间序列可以决定下一步的前提下,每个神经元t时刻的输出转化为t+1时刻输入的一部分,如图3所示,设RNN神经元接受当前时刻向量表示的信息xt∈Rk,上一时刻的输入为ht-1∈Rk,运算后得到输出ht∈Rk,传统RNN是一种单向神经网络,但当前事件同时与以后的事件存在密切联系,双向循环神经网络通过增加由后向前传的隐藏层来处理此类情况。随着输入序列增长,普遍存在与预测剩余时间无明显因果关系的序列片段,严重影响RNN的预测精度。为解决这一问题引入注意力机制[14],技术原理是把注意力放到关键部分,而不是序列的全部,其最核心的技术是实现记录元素权重的参数矩阵及权重向量,同时拟合每一个元素在序列中的重要程度,然后按照权重参数将序列重新组合,权重参数是注意力分配系数。本文尝试引入不同类型RNN预测教育过程剩余时间,其中添加注意力机制的双向循环神经网络(BiRNNAtt)结构如图4所示,将该模型删除或替换其中机制可以转化为其他结构的RNN预测模型。 图3 RNN神经元 图4 添加注意力机制的双向RNN结构 3.2.1 事件在BiRNNAtt中的表示方式 本文所用循环神经网络以任意轨迹前缀标记其剩余时间组成的∪Dk做为输入,其中(σ(k), remain_time(σ,k))∈∪Dk,σ(k)= 3.2.2BiRNNAtt的上下文表示 3.2.3 注意力机制在BiRNNAtt中的轨迹表示 得到轨迹前缀每个t时刻发生事件的上下文表示后,进而计算完整轨迹的表示,具体方法为 (1) 式中:at表示t时刻发生事件的上下文权重值,其含义是轨迹中第t个事件对预测剩余时间的影响程度,引用双层感知机网络计算上下文的权重,即 (2) 式中:gatt为注意力机制权重向量; 根据循环神经网络中学生在线学习轨迹的表示方式,使用全连接网络搭建预测模型,并且为了避免梯度消失、梯度爆炸,减小运算复杂程度,引入RELU线性整流函数。综合式(1)、式(2)所述,学生在线剩余学习时间的计算方法为 remain_time(σ,k)=gT·RELU(W·v+b)。 (3) 本实验引用在线学习微处理器系统设计课程的数据集[15],对学生学习该课程的在线剩余时间进行预测。该课程包含6个章节(Session1—Session6),每章包含4~6个小节,其中包含学生观看教学视频、建模、实时测试、翻阅资料、点击网页的事件记录,学生在线学习时常最大不超过5 h,原始数据集转化为事件日志之后的概况见表1。事件数和事件类型数偏多且轨迹过长,平均每条学生轨迹有1 000个事件且包含28个以上的事件类型,因此需要将事件粒度提升,减少轨迹的事件数量,并将事件类型数减少到7~10。 表1 在线学习事件日志规模 为了提升预测效果,在连续且活动名重复的多个事件转化为一个事件的前提下,将事件粒度放大到每一节课为一个事件,并且设每一节(section)第一个事件的开始时间作为该节开始时间,最后一个事件的结束时间为该节结束时间。处理后的轨迹长度由1 000到1 200不等缩小至30到100个事件之间,获取输入事件日志的具体算法如算法2所示。 算法2 GetInputLog输入:事件日志 L;寄存事件的栈Stack;输出:粒度提升后的LNew;1.C(e)= ( #section(e), #time.start (e), #time.end (e) );2.FOR σ IN L DO: 3.NewTrace=ϕ; Stack=ϕ4.FOR e IN σ DO:5. IF Stack!=ϕ && Stack.top().section!= e.section THEN:6.Stack.top().start_time=Stack.bottom().Start.time 7.END IF8.NewTrace=NewTrace∪C( Stack.top( ) )9. Stack.PopAll( ) END FOR10. Stack.push(e)11.LNew=LNew∪NewTrace12. END FOR13.RETURN LNew; 本实验使用平均绝对误差MAE作为预测结果的评价方式,其值越低说明预测结果的误差越小,若σ表示数据集中已完成的学生轨迹,则MAE计算方法为 (4) 式中f(σk)表示RNN对学生轨迹前缀σk的预测结果。 本实验剩余时间的单位为min,设置训练集比率0.78,测试集比率0.22,学习率控制在(0.000 1, 0.01)。在本实验中模型隐藏层的维度为5,最大epoch数为500,batch_size为20,dropout为1。全部预测结果如图5所示,所用方法对Session4数据集中学生剩余学习时间的预测最为准确,所有模型在该章的MAE值均小于18 min,且最优模型的MAE值小于12 min,表明预测结果十分接近真实情况,体现了本文所提供策略的有效性。由于时间预测的最终目的是对学生整个学习过程进行早期推荐与规划,因此将前缀长度设置为[3,30],可能是训练集中轨迹前缀长度设置较短,远小于某些轨迹的真实长度,导致某些模型的观测结果较差。实验结果表明,不同模型在不同数据集中的表现存在差异,BiLSTM预测Session1、Session2、Session3数据集的剩余时间比较精确; (a)Session1的预测误差 (b)Session2的预测误差 本节解析当学生行为发生偏移时,利用过程模型推荐与该学生轨迹前缀吻合且剩余时间误差最小的优秀学生学习轨迹,推荐架构如图6所示,因果关系用黑色箭头表示,渐近色箭头表示两者之间存在协同。 图6 教育过程推荐架构 第一步,训练预测剩余时间的RNN模型,从日志中选取优秀学生的学习轨迹并调用Inductive Miner[16]挖掘Petri网; 假设实时轨迹定义为CurrentTrace,优秀学生轨迹定义为Lo,预测模型定义为Rnn,推荐轨迹定义为BetterTrace,则推荐策略如算法3所示,具体实现步骤如算法4所示。 算法3 Recommend输入:静态变量CurrentTrace , Lo , Rnn;输出:BetterTrace;1.PredicatedTime=Rnn.remain_time(CurrentTrace,Current-Trace.length)2.C(e)= ( #section(e), #time.end (e))3.FOR σj IN LoDO:4. i=0 ;flag=0;5.FOR e IN σjDO:6.IF C(CurrentTrace.GetEvent(i++))!= C(e) THEN:7.flag=1 BREAK 8.END IF9.END FOR10.IF flag==1&& PredicatedTime-remaintime(σj,k)|=|min(PredicatedTime -remain_time(σ,k))| THEN://更新实时轨迹11. CurrentTrace= CurrentTrace - CurrentTrace.get(Current-Trace.Length)//返回推荐结果12.Return BetterTrace=σj13.END IF 14.END FOR 算法4 Recommend Trace By Remain Time输入:事后事件日志L,间歇且持续的实时事件CurrentEvent, CurrentTrace表示CurrentEvent发生前的轨迹前缀;输出:推荐学习轨迹BeterTrace;1.Rnn=TrainedRemainPredicationRNNModel();2.Lo=GetBetterStudentLog();3.PetriNet=InductiveMinner(Lo);4.P= PetriNet.StartPlace();5.C(e)=( #section(e), #time.start(e))//检查实时轨迹是否符合与模型一致6.FOR e IN CurrentTrace DO:7.FOR t IN P.OutTransitions () DO:8. IF t.Label== C(e) THEN:9. P=t.OutPlace()10.ElSE IF RETURN “ error !”11.END IF END FOR 12.END FOR //检查实时事件执行时间是否过短,是则提示13.ei=CurrentTrace.get(CurrentTrace.Length)14.ej=CurrentTrace.get(CurrentTrace.Length-1)15.Time= ei.start.time - ej.start.time 续表 本文系统介绍了教育过程挖掘的发展现状与研究成果,同时构想过程挖掘技术对在线教学场景提供支持,将学生在线学习事件日志的粒度提升,并引入不同类型的循环神经网络预测学习过程的剩余时间,预测结果总体上表现较好,最后设计教育过程挖掘与剩余时间预测相结合的应用架构。本文不足之处:其一,仅考虑单一轨迹维度,并未引入资源等其他维度使得预测结果更为准确,整合在线学习轨迹和其他属性应更具有说服力;
T={a,c,d,b};
P={start, p1, p3, p4, p2, end }。
3.1 获取训练集、测试集

3.2 循环神经网络

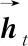
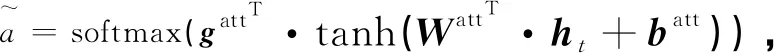
batt为偏置参数;
Watt为权重矩阵;
gatt、batt、Watt参数值对任意输入共享;
tanh是单调递增且值域为(-1,1)的双曲正切函数。3.3 剩余在线学习时间预测
4.1 学生事件日志粒度的提升

4.2 评估标准
4.3 实验设置
GRU在Session4、Session6数据集的预测表现较好;
LSTM在 Session5数据集的表现较好。在一定程度上反应不同的数据集适合不同的RNN。

5.1 设计思路
第二步,接收教育信息系统传来的实时事件,并检测Petri网内是否能够找到契合该事件的下一个变迁,如果是,则当前库所指向该下一个变迁的输出库所,如果否,则进行下一步;
第三步,检测当前轨迹前缀是否用时过短,若学生实时轨迹比任何前缀相同的优秀学生都短则提醒,由于算法从学生发生的第一个事件开始监听,因此只检测最后两个事件就可以判断学习时间是否过短,如果监听的实时轨迹与Petri网不契合时,调用RNN模型预测该轨迹从开始事件到当前实时事件的上一个事件组成前缀的剩余完成时间,并搜索在剩余用时误差最小的优秀学生轨迹并推荐。与工业生产过程、企业办公过程不同的是,当学生行为与过程模型发生偏移时,学生可以立刻调整,纠错代价接近于无,因此推荐较优学习路径的时延不影响学生的全局学习效果,由于算法设定,学生必须按照模型给定的行为参与学习,且由于过程模型出自优秀学生的在线学习事件日志,必然可以在优秀学生事件日志中找到与实时轨迹相吻合的推荐轨迹,且这种推荐策略省略了大量计算,因此推荐速度明显快于智能计算方法,更适合教学这种实时场景。5.2 架构实现



其二,如何预先对数据集进行评估用以选择最合适的预测模型;
其三,如何构造更合适的教学模拟环境,从而对教育过程挖掘方法进行更充分的验证,以及如何通过教学环境搭建更标准的推荐机制。未来研究工作将着重于以上三个方面。